
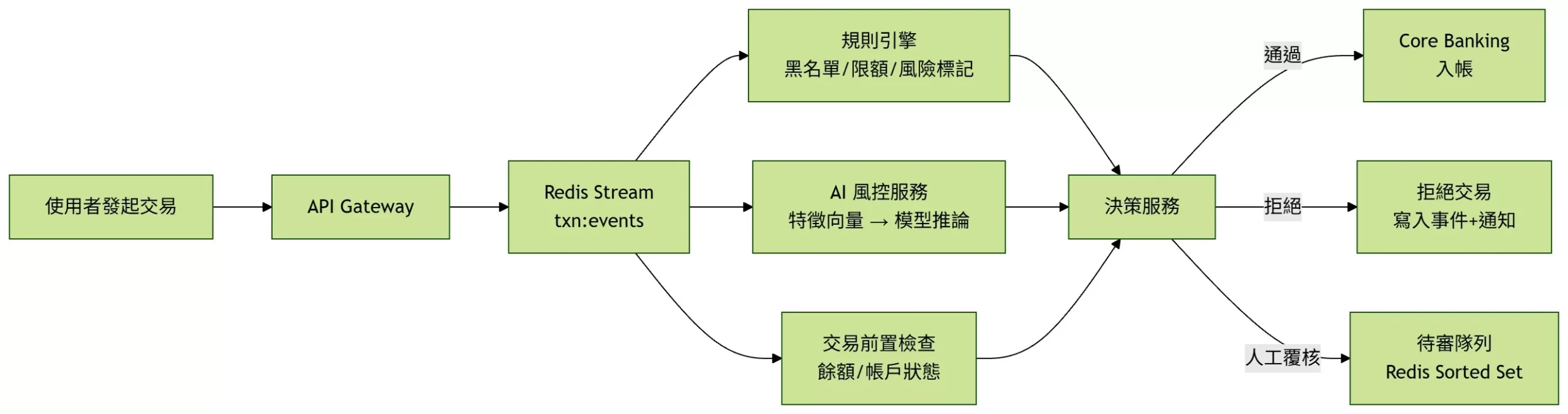
整體架構:事件驅動+多層快取+模型推論
高層流程可以簡化成幾件事:交易先進事件流,風控服務並行處理,再由決策服務彙整結果,最後只將確認可入帳的交易送進 Core Banking。
把 交易請求 先寫進事件流,例如 Redis Stream,避免所有檢查一開始就綁死在同步呼叫上。
風控拆成多條路徑 並行處理,包含規則引擎、AI 模型與基本交易檢查。
把結果集中回 Redis,最後由決策服務快速彙整並做出綜合判斷。
真正寫進 Core Banking 的,只保留最終確認要入帳的交易。
架構流程圖
事件流:金融交易的「神經系統」
在即時風控場景中,交易不應該被一條同步鏈路一路拖慢。Redis Stream 可將交易轉為事件流,讓規則引擎、AI 風控、行為分析與審計寫入並行處理。
傳統作法的問題:同步鏈路越堆越長
一筆交易在傳統架構中,往往需要依序完成多個檢查。只要其中一個服務變慢,整條鏈路就會被拖住。
總延遲:約 380ms
Redis Stream 解法:把風控拆成事件流
交易先被寫入 Stream,後續由多個消費者各自讀取與處理。每個模組可以獨立擴充,不必全部塞在同一條同步鏈路上。
用 Redis Stream 把風控拆成並行處理
從交易寫入、消費者並行處理,到結果回寫與決策服務彙整,可以形成更穩定、可擴充的即時風控流程。
交易先寫進事件流
將交易金額、商戶、裝置、IP 與時間戳寫入 Redis Stream。
多個消費者並行處理
規則引擎、AI 風控、行為分析與審計寫入,可各自獨立讀取事件。
結果回寫給決策服務
各服務將結果寫回 Redis,決策服務再依決策矩陣做最終判斷。
XADD txn:events *
user_id "U123456"
amount 5000
merchant "7-11"
device_id "D789"
ip "1.2.3.4"
timestamp 1234567890XREADGROUP GROUP risk-engine consumer1
STREAMS txn:events >決策服務如何做判斷?
事件流處理視圖
.webp)
實際觀察到的效果
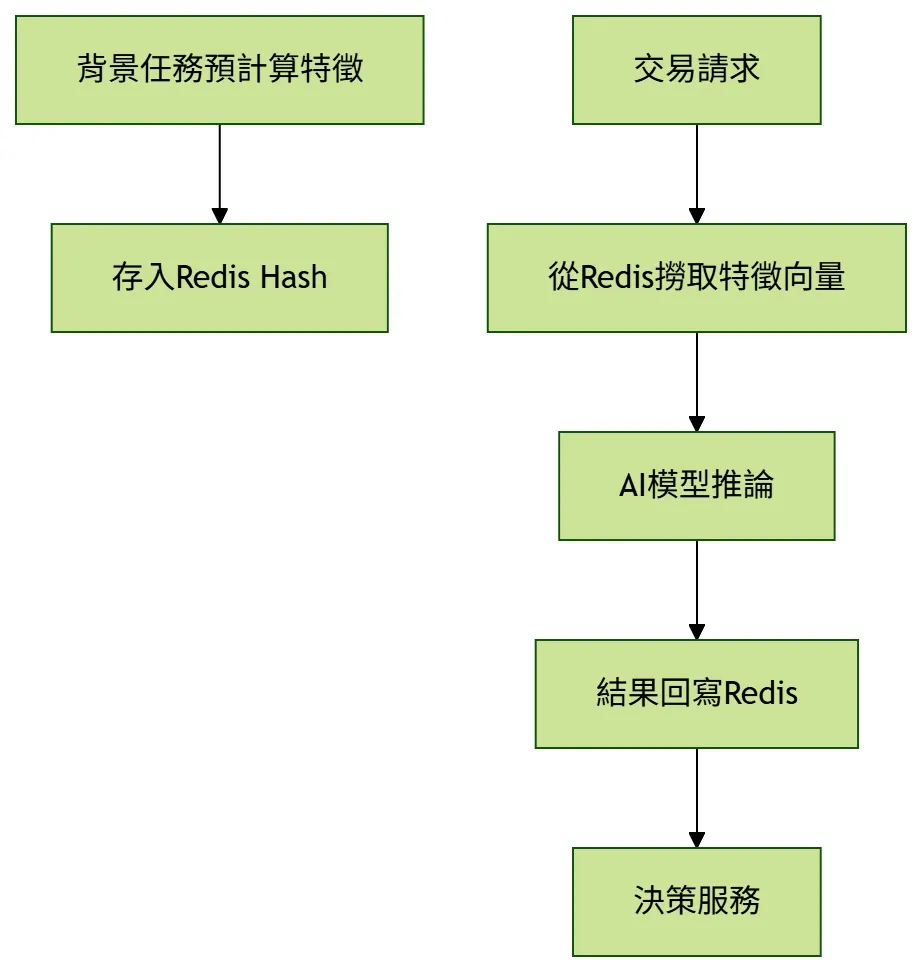
特徵向量快取:讓 AI 模型「有料又不塞車」
成熟的詐欺偵測模型通常需要大量即時特徵。Redis 可作為 Feature Store,先將高頻特徵算好並放進快取,讓模型推論時快速取用。
為什麼特徵工程常卡在風控關鍵路徑?
一筆交易如果要臨時計算近 7 天交易次數、近 30 天平均單筆金額、夜間交易比例、跨境交易頻率、裝置變更次數與黑名單關聯度,背後往往需要多次查詢與聚合。
Redis Feature Store:先算好,推論時直接取
把常用特徵預先寫入 Redis Hash,推論時一次撈完,避免在交易同步鏈路中跑多個 JOIN 與聚合查詢。
用 Redis 當 Feature Store 的四個關鍵動作
從預先儲存特徵、推論時一次撈完,到用增量維持新鮮度,讓 AI 風控模型可以在低延遲下取得足夠資料。
預算特徵
將常用特徵放進 Redis Hash,作為推論時的即時資料來源。
一次撈完
推論時用 HGETALL 快速取得使用者特徵向量。
增量更新
交易完成後用 HINCRBY、HINCRBYFLOAT 更新簡單指標。
擴充來源
把裝置、IP、地理位置也納入特徵來源,輔助即時判斷。
Key: features:{user_id}
Fields: {
txn_count_7d: 23,
avg_amount_30d: 1500,
night_txn_ratio: 0.12,
cross_border_count: 2,
device_change_count_30d: 1,
risk_network_score: 0.05,
last_updated: 1234567890
}
TTL: 1 小時HGETALL features:{user_id}
→ 通常 < 1msHINCRBY features:{user_id} txn_count_7d 1
HINCRBYFLOAT features:{user_id} total_amount_7d 5000Key: device:{device_id}
Value: {
first_seen: timestamp,
user_count: 1,
suspicious_activity: false
}
Key: ip:geo:{ip}
Value: {country: "TW", city: "Taipei", isp: "Chunghwa"}交易進來時,風控可以順便判斷
Feature Store 視圖
實際觀察到的效果
模型推論結果暫存:不要每一筆都「重新算一遍」
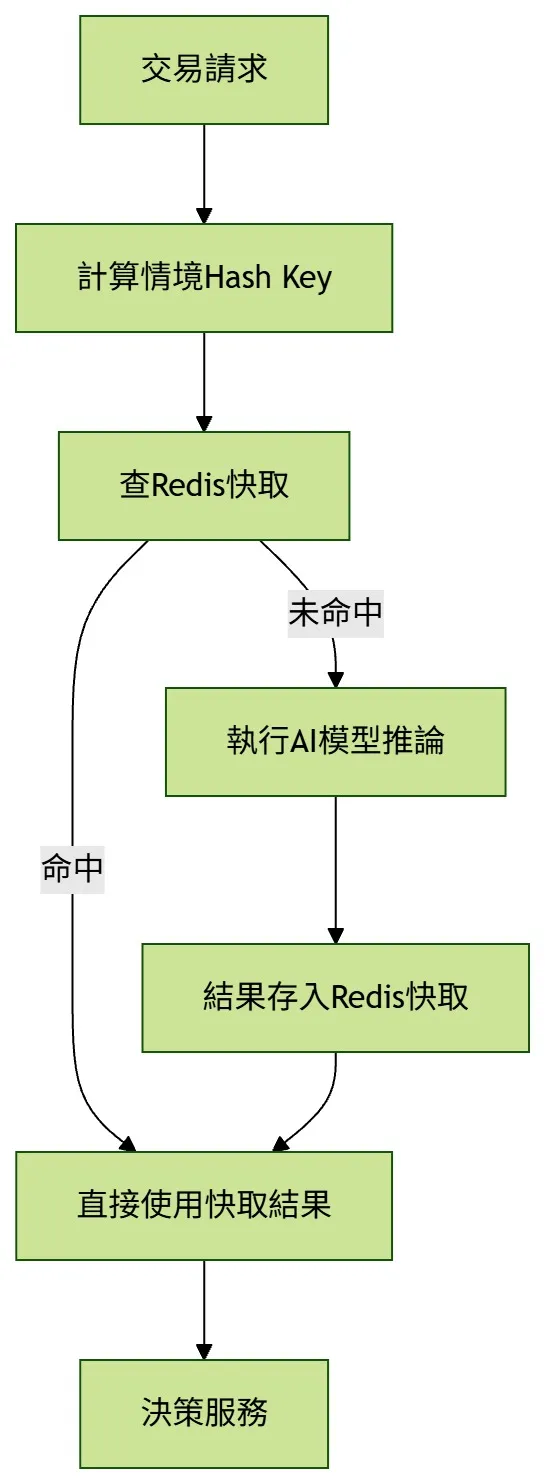
在短時間內連續發生的相似交易,不一定需要每次都重新呼叫模型。透過 Redis 快取模型推論結果,可降低重複計算成本,並穩定高峰時段的風控延遲。
問題:同一使用者短時間多筆交易,模型被重複轟炸
以便利商店繳費、停車、捷運加值為例,同一位使用者可能在 5 分鐘內連刷好幾筆。如果每一筆都重新送模型推論,就會造成計算資源浪費與延遲累積。
解法:把模型結果快取起來,再搭配合理失效策略
先定義交易情境的 Hash Key,將模型分數、風險等級與模型版本暫存在 Redis。當交易情境相似且快取尚未過期時,就可直接沿用結果。
模型結果快取的四個設計重點
從情境 Hash Key、查快取、主動失效,到多模型結果整合,讓決策引擎能以一次 Redis 查詢取得完整風險分數。
定義情境 Key
依交易類型、金額區間、時段等因素組合 context_hash。
未命中才推論
命中且未過期就直接使用,未命中才呼叫模型。
主動失效
當使用者行為突變時,刪除相關快取並重新判斷。
多模型統查
把詐欺、洗錢、信用風險分數整合到同一個 Composite Key。
Key: ml:score:{user_id}:{context_hash}
Value: {
fraud_probability: 0.15,
risk_tier: "low",
model_version: "v2.3",
features_snapshot: {...},
created_at: timestamp
}
TTL: 5 分鐘1) 先查 ml:score:{user_id}:{context_hash}
2) 命中且未過期 → 直接用
3) 未命中 → 呼叫模型 → 結果寫回 Redis → 回傳DEL ml:score:{user_id}:*Key: risk:composite:{user_id}
Fields: {
fraud_score: 0.15,
aml_score: 0.08,
credit_score: 720
}什麼時候需要讓快取主動失效?
推論快取流程圖
某 FinTech 實際數據
黑名單與關聯網路:
關係複雜,但查詢要在「秒級」
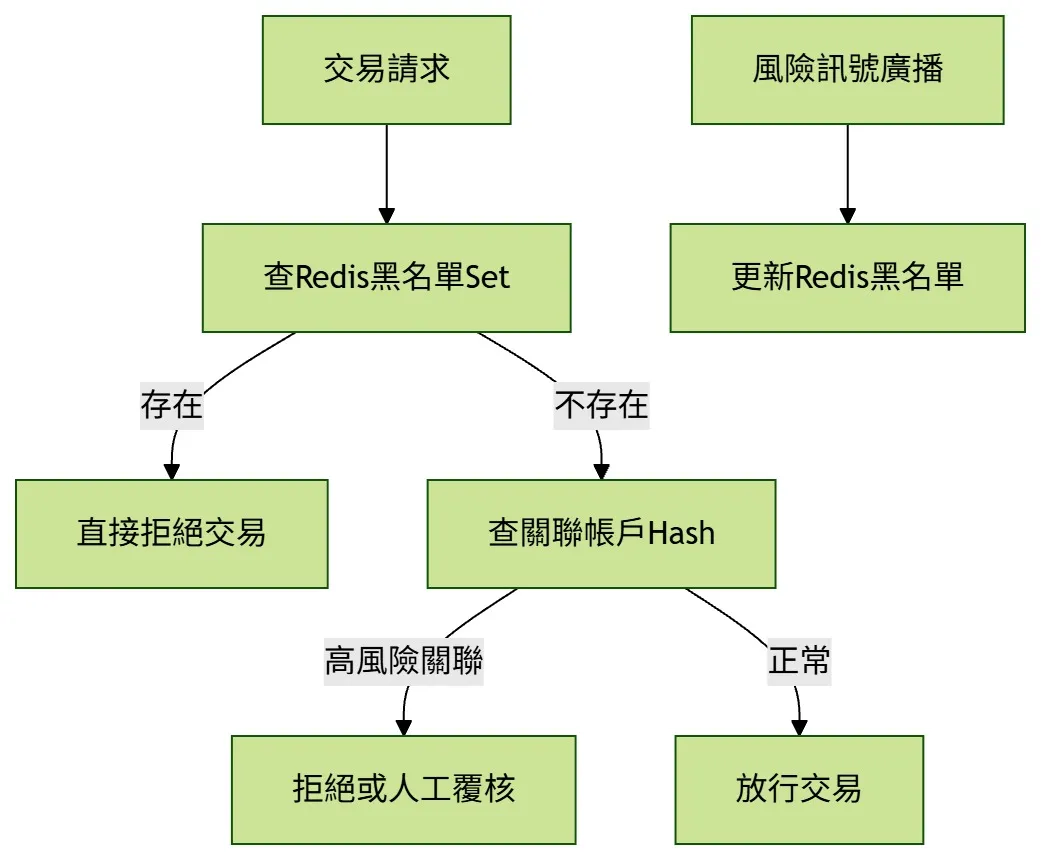
現實世界的詐欺不是單一帳戶,而是跨帳戶、跨裝置、跨 IP 的關聯網路。Redis 可用於管理黑名單與關聯關係,讓風控系統在交易當下快速判斷風險。
現實世界的詐欺,不是單一帳戶,而是網路
常見樣態包括帳戶層層轉移、同一裝置登入多個帳戶、同一 IP 在短時間操作多個帳戶。若交易當下還要靠傳統 SQL 做關聯查詢,容易拖慢判斷。
Redis 解法:把黑名單與關聯關係放進快速查詢結構
用 Set 管理分級黑名單,用 Hash 或 Set 建立帳戶、裝置、IP 之間的關聯。交易進來時即可快速檢查是否命中高風險網路。
用 Redis 管理黑名單與關聯關係
從分級黑名單、關聯帳戶快取,到裝置指紋偵測與風險訊號廣播,讓交易判斷不再依賴昂貴的即時關聯查詢。
分級黑名單
將已確認詐欺、高度可疑、列管觀察拆成不同 Set。
關聯帳戶快取
把同一網路中的關聯帳戶整理成可快速查詢的集合。
裝置指紋偵測
用 Sorted Set 記錄裝置與帳戶的使用關係與時間序。
風險訊號廣播
發現重大風險時,用 Pub/Sub 讓各服務即時更新狀態。
Key: blacklist:confirmed (已確認詐欺)
Type: Set
Key: blacklist:suspicious (高度可疑)
Type: Set
Key: blacklist:monitoring (列管觀察)
Type: SetSISMEMBER blacklist:confirmed {target_account}
→ 命中就直接拒絕
SISMEMBER blacklist:suspicious {target_account}
→ 要求額外驗證Key: network:{account_id}
Type: Set
Members: {related_account1, related_account2, ...}Key: device:accounts:{device_id}
Type: Sorted Set(以時間排序)
Members: {account1, account2, ...}PUBLISH risk:alert '{"account": "A123", "risk": "confirmed_fraud", "network": [...]}'交易當下可以快速判斷什麼?
黑名單與關聯網路視圖
某銀行導入後的觀察
人工覆核隊列與案件追蹤:
讓審核員處理最該優先的案件
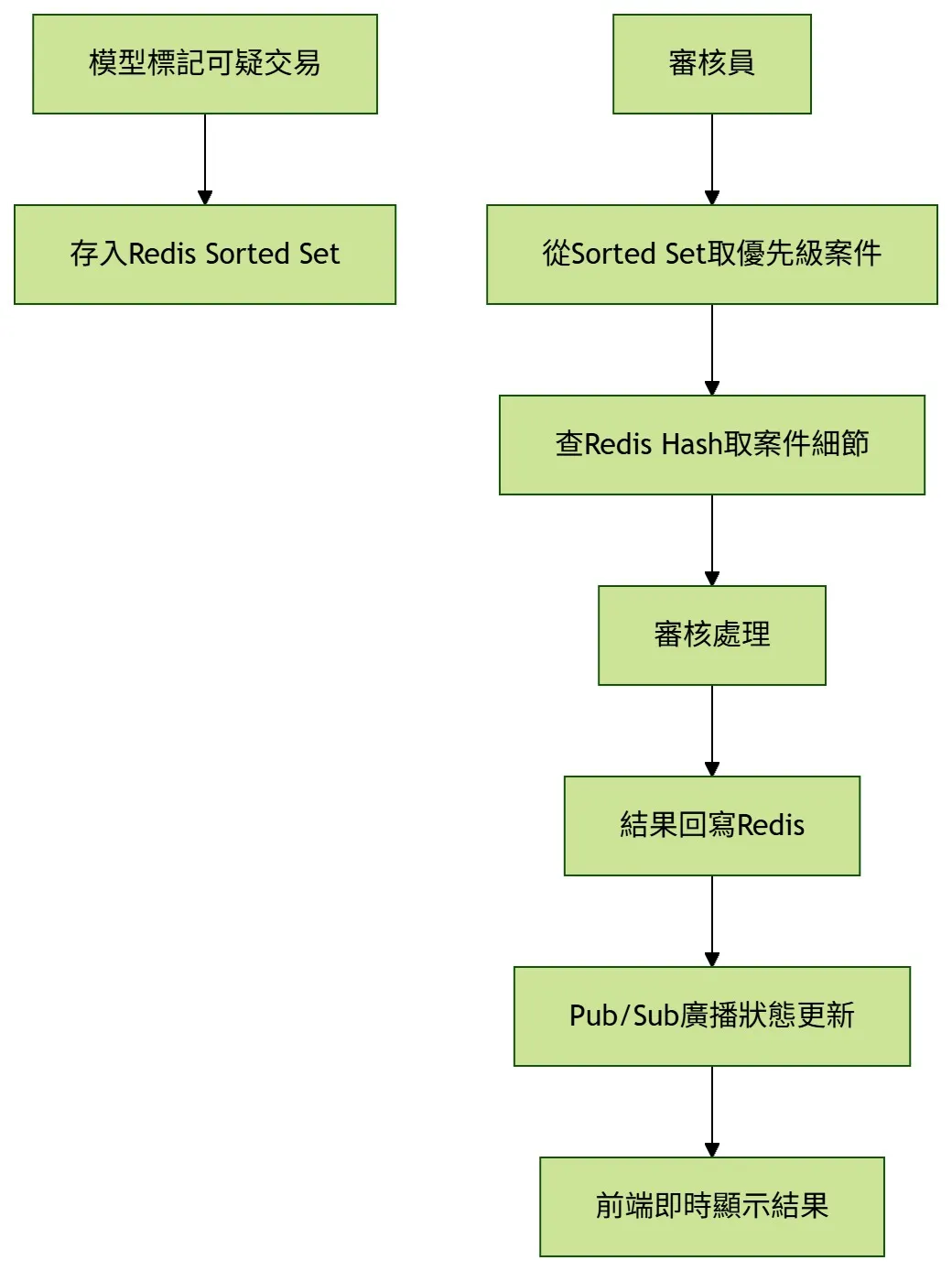
當模型判斷不確定,或交易落在灰色區間時,許多案件會進入人工覆核。Redis Sorted Set 可協助建立優先級隊列,讓高風險、高金額、急迫案件優先被處理。
傳統待辦表的幾個痛點
如果人工覆核案件只放在一般資料庫表格中,容易遇到排序不即時、分工不平均與狀態同步延遲等問題。
Redis 解法:用 Sorted Set 建立優先級隊列
將案件依風險分數、金額權重與等待時間計算優先級,放進 Redis Sorted Set。審核員每次取出最高分案件,避免重要案件被埋在隊列後方。
用 Redis Sorted Set 做優先級隊列
從案件排隊、案件細節、狀態通知到審核工作量追蹤,讓人工覆核流程更透明,也更容易把有限人力放在高風險案件上。
案件排入隊列
以風險分數與金額權重計算 score,存入 Sorted Set。
優先取件
審核員取出目前分數最高的案件,先處理最急迫風險。
狀態即時更新
覆核完成後寫回 Redis,並透過 Pub/Sub 通知前端。
追蹤工作量
紀錄各審核員工作量,讓系統能更平均分配新案件。
Key: review:queue
Type: Sorted Set
Score: 風險分數 * 1000 + 金額權重
Members: {case_id1, case_id2, ...}ZPOPMAX review:queue 1
→ 取出當下優先分數最高的案件Key: case:{case_id}
Value: {
user_id,
amount,
merchant,
risk_score,
ai_reason,
assigned_to,
status,
created_at
}
TTL: 24 小時HSET case:{case_id} status "approved"
PUBLISH case:updates '{"case_id": "C123", "status": "approved"}'Key: reviewer:workload
Type: Hash
Fields: {reviewer1: 5, reviewer2: 3, reviewer3: 8}這樣做能改善什麼?
人工覆核隊列視圖
某數位銀行實際效果

想評估 Redis + AI 如何導入金融即時風控?
從事件流、特徵快取、模型推論暫存,到黑名單關聯網路與人工覆核隊列,Redis Enterprise 可協助金融機構打造低延遲、高可用且符合治理需求的即時風控架構。
若您正在評估智慧金融、小額信貸、微型保險、支付交易或詐欺偵測場景,宏虹可依據既有系統架構與業務流程,協助進行導入評估、架構規劃與 POC 技術驗證。


