
Artificial Intelligence is in full swing, and while language models interact with humans in real-time, how can they be without the support of a highly efficient and scalable data layer? Combined with the reliable Redis, Google's Big Language Model realizes efficient and scalable semantic search, retrieval enhancement generation, LLM caching, memory and persistence.
I. Language Model Components
The ability of applications to generate, understand, and use human language is becoming increasingly important. From customer service robots to virtual assistants to content generation, the demand for AI application functionality spans a wide range of domains, and it's all possible thanks to foundational models such as Google's PaLM 2, which are fine-tuned to produce content that resembles the style of human expression.
In this dynamic environment, two fundamental components, the base model and the high-performance data layer, remain key to creating high-performance, scalable language modeling applications.
1. Base model:
Base models are the cornerstone of generative AI applications, and large-scale language models (Large Language Model (LLM) is a subset of this.LLM has been trained through extensive textual training to be able to produce contextually relevant text with a similar style of human expression for a variety of tasks. Improving these models to make them more complex allows the application to respond to user input more concisely and efficiently. The language model chosen significantly affects the performance, cost, and quality of service of the application.
However, while powerful, models such as PaLM 2 have limitations, such as being insufficiently relevant when there is a lack of domain-specific data, and may not be able to present new or accurate information in a timely manner.LLM has a hard limit on the length of context (i.e., the number of phrases) that can be processed in the prompts (prompts), and in addition, training or fine-tuning of LLM requires a large amount of computational resources, which can increase the cost dramatically. Striking a balance between these constraints and advantages requires a careful strategy and the support of a strong infrastructure.
2. High-performance data layer
The efficient LLM application is backed by a scalable, high-performance data layer that ensures high transaction speeds and low latency, which is critical to maintaining smooth user interactions. It plays a key role in the following areas:
- Cache Estimation Request Response or Embedding
- Persistent history of past interactions
- Conduct semantic searches to retrieve relevant context or knowledge
Vector databases have become a popular data layer solution, and Redis' investment in vector search long before the current vector database boom reflects our experience, especially in performance. Redis' experience with vector search is reflected in the just-released Redis 7.2 release, which includes a preview of scalable search capabilities and a 16x increase in queries per second compared to the previous release. Redis' experience with vector searches is evident in the just-released Redis 7.2 release, which includes a preview of the scalable search feature that improves queries per second by a factor of 16 over the previous version.
Base models and vector databases play a crucial role in LLM applications across different industries, and as a result, they are generating a lot of interest and hype in the industry. For example, some of the newer standalone vector database solutions (e.g., Pinecone) have announced huge funding rounds and have invested a great deal of effort to win the attention of developers. However, with new tools popping up every week, it's hard to know which ones will actually fulfill an organization's needs.
GCP (Google's Google Cloud Platform ) is differentiated by its unified offering, which combines a powerful base model, a scalable infrastructure, and a set of tools for tuning, deploying, and maintaining these models.This ensures the highest level of data security and privacy.
But to truly realize the potential of these advances, a high-performance and scalable data layer is essential, and that's where Redis comes in.
3A Reasoning Architecture for Extensible Language Modeling Applications
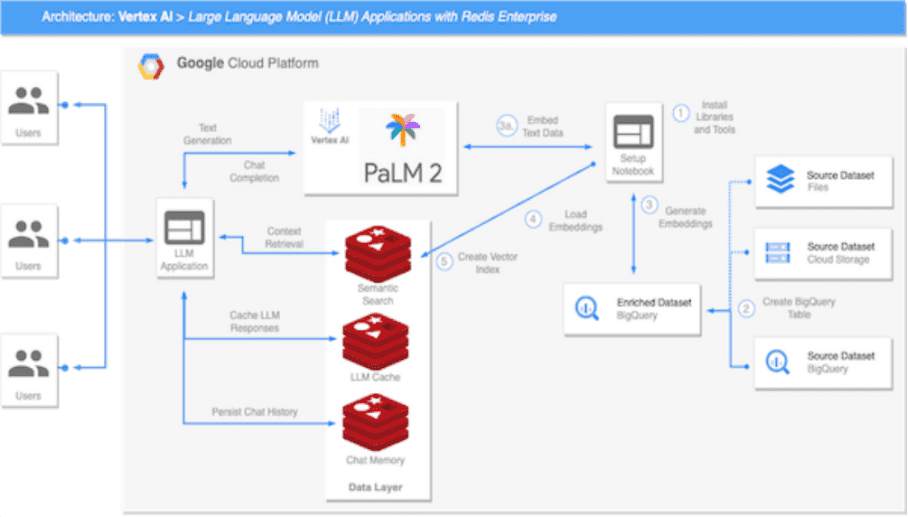
The reasoning architecture presented here is applicable to the Generalized Language Model use case. It uses a combination of Vertex AI (PaLM 2 base model), BigQuery and Redis Enterprise.
You can follow theOpen Source GitHub WarehouseYou can set up this LLM structure step by step in Colab Notebook. (See the end of the article for the project link)
- Install libraries and tools: Install the required Python libraries, use Vertex AI for authentication, and create a Redis database.
- Creating a BigQuery Form: Load the dataset into the BigQuery form in your GCP project.
- Generated Text Embedding: Loop through the records in the dataset to create a text embedding using the PaLM 2 Embedding API.
- Load Embedding: Loads text embedding and some metadata into a running Redis server.
- Creating a Vector Index: Execute the Redis command to create a schema and a new index structure to enable real-time searching.
After completing the necessary setup steps, the architecture can support a variety of LLM applications such as chatbots and virtual shopping assistants.
Applying Redis to the Language Model (LLM)
Even experienced software developers and application architects may be unfamiliar with this new area of knowledge, and this brief summary should help you get up to speed quickly.
1, the use of Redis to achieve efficient and scalable semantic search
Semantic search extracts semantically similar content from a large corpus of knowledge. In this process, knowledge is transformed into a vector of numerical embeddings that can be compared to find the most relevant contextual information to the user's query.
As a high-performance vector database that specializes in indexing unstructured data for efficient and scalable semantic search, Redis enhances an application's ability to quickly understand and respond to user queries, and its powerful search indexing capabilities enable fast responses and accurate user interactions.
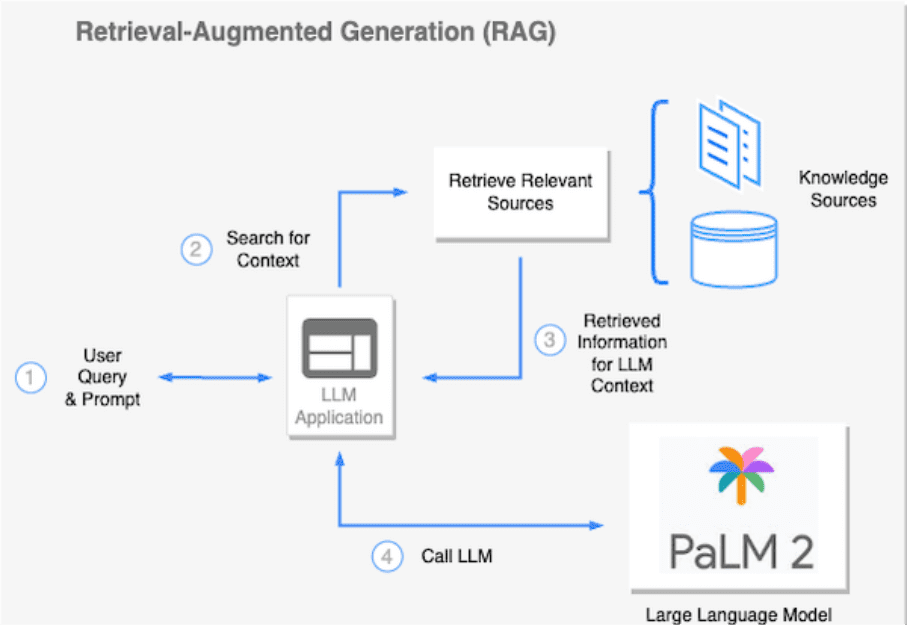
2、Using Redis to realize retrieval enhancement generation
The Retrieval-Augmented Generation (RAG) approach utilizes methods such as semantic search to dynamically annotate factual knowledge before delivering prompts to the LLM. This technique minimizes the need to fine-tune the LLM on proprietary or frequently changing data.RAG allows for contextual enhancement of the LLM so that it can better handle the task at hand, such as answering a specific question, summarizing the retrieved content, or generating new content.
As a vector database and full-text search engine, Redis helps RAG workflows run smoothly. Due to its low-latency data retrieval capabilities, Redis is often the tool of choice for this task. It ensures that the language model obtains the required context quickly and accurately, facilitating the efficient execution of tasks by AI applications.
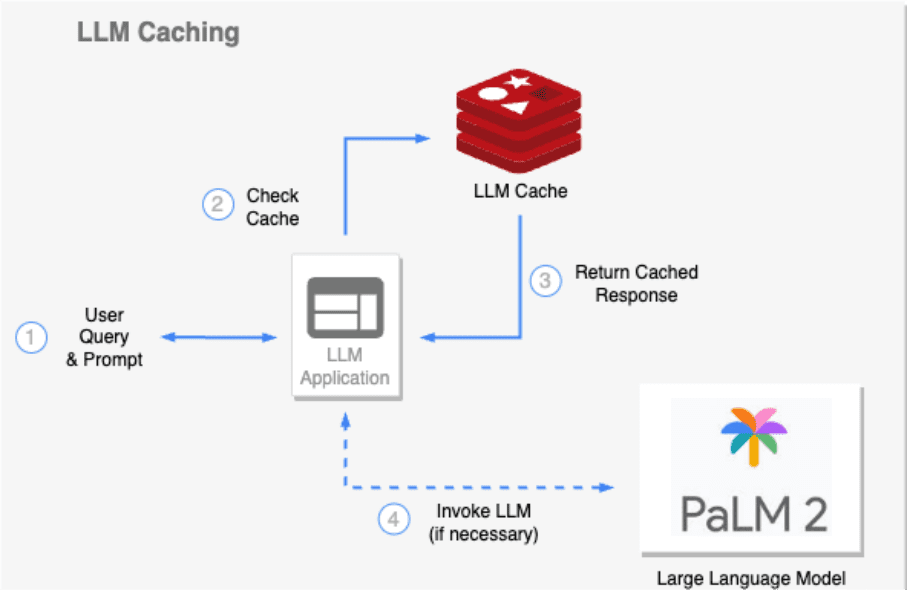
3、Use Redis to realize the LLM caching mechanism
Caching is a powerful technology that enhances LLM's response capability and computing efficiency.
Standard caching provides a mechanism for storing and quickly retrieving pre-generated responses to common queries, thereby reducing computational load and response time. However, when using human language in a dynamic dialog context, exact matching queries are rare, and this is where semantic caching comes into play.
Semantic caching understands and utilizes the underlying semantic meaning of a query. Semantic caching recognizes and retrieves cached responses that are semantically similar enough to the input query. This capability greatly increases cache hit rates, further improving response times and resource utilization.
For example, in a customer service scenario, multiple users may ask similar frequently asked questions using different wording. Semantic caching allows LLM to respond to these questions quickly and accurately without redundant computation.
Redis is ideally suited for implementing caching in LLM, with a robust feature set that includes support for time-to-live (TTL) and eviction policies for managing temporary data. Combined with the semantic search capabilities of its vector database, Redis can retrieve caching responses efficiently and quickly, dramatically improving LLM response times and overall system performance, even under heavy load.
4. Using Redis to realize memory and persistence
Retaining metadata about past interactions and conversations is essential to ensure contextual coherence and personalized conversations, but LLM does not have adaptive memory, so relying on a reliable system for rapid conversation data storage is critical.
Redis provides a powerful solution for managing LLM memory. It provides efficient access to chat history and session metadata on high demand. It provides efficient access to chat history and session metadata on high demand.Redis uses its data structure storage to handle traditional memory management, while its vector database capabilities help extract semantically relevant interactive content.
Application Scenarios of LLM
1. File Search
Some organizations deal with large volumes of documents, and LLM applications can be a powerful tool for document discovery and retrieval, with semantic searches helping to pinpoint relevant information from an extensive corpus of knowledge.
2、Virtual Shopping Assistant
LLM can support sophisticated e-commerce virtual shopping assistants that can understand customer questions, provide personalized product recommendations, and even interact in real-time simulated conversations through contextual understanding and semantic search.
3、Customer Service Assistant
Deploying LLM as a customer service agent can revolutionize customer interactions. In addition to answering common questions, the system can conduct complex conversations, provide customized assistance to customers, and learn from past customer interactions.
Redis and Google Cloud: A Strong Partnership
1. Based on knowledge
GCP and Redis allow LLM applications to be more than just advanced text generators. By rapidly injecting specific knowledge from your own domain at runtime, they ensure that your applications provide knowledge-based, accurate and valuable interactions that are specifically tailored to your organization's knowledge base.
2、Simplify the structure
More than just a key-value database, Redis is a versatile tool for real-time data that greatly simplifies your architecture by eliminating the need to manage multiple services for different use cases. As a tool that many organizations already trust for caching and other needs, the integration of Redis in LLM applications has a seamless scaling effect.
3. Optimize performance
Redis is synonymous with low-latency and high-throughput data structures. When combined with GCP's superb computing power, you have an LLM application that is not only smart, but responsive, even under heavy load.
4. Enterprise-level capabilities
Redis is a time-proven open source database core that reliably serves Fortune 100 companies worldwide. Backed by Redis Enterprise's five-nines (99.999%) availability and supported by GCP's robust infrastructure, you can have complete confidence that it will fully meet your organization's needs.
5. Accelerating the listing process
With Redis Enterprise, you can focus more on building LLM applications and less on database setup. This ease of integration accelerates time-to-market and gives your organization a competitive advantage.
While new vector databases and generative AI offerings may be garnering a lot of attention in the marketplace, the reliable combination of GCP and Redis is more than trustworthy. These time-tested solutions aren't going away anytime soon, and they're ready to power your LLM applications today and for years to come.



